
Au cours des dernières années, la plupart des entreprises ont dû effectuer une transformation numérique. De ce fait, elles recueillent aujourd'hui un volume de données considérable. Ces données sont cruciales pour l'élaboration de stratégies et la prise de décision. Cependant, lorsque le volume de données devient trop important, il peut devenir difficile pour une entreprise de les gérer et surtout de les activer de manière efficace.
C'est pourquoi un outil comme Airbyte peut s'avérer très utile.
Airbyte est une technologie fondée en 2020 à San Francisco, aux États-Unis. Lancé avec l’objectif de simplifier la création de pipelines de données, Airbyte permet de choisir parmi près de 300 connecteurs disponibles et ainsi d'envoyer les données vers n'importe quelle destination, sans avoir à se soucier de la maintenance.
Le but de cet article est de présenter Airbyte et de démontrer son fonctionnement à l'aide d'un tutoriel.
Dans cet article, retrouvez :
- Comment Airbyte simplifie-t-il la création de pipelines ?
- Dans quel but faire un pipeline ELT ?
- Coûts associés aux pipelines ELT traditionnels
- Avantages d'Airbyte
- Démonstration
Extract, Load, Transform
Tout d'abord, il faudrait comprendre ce qu'est un pipeline ELT (à ne pas confondre avec ETL où la transformation se fait avant le fait de charger les données).
Un pipeline, ou bien un conduit de données, permet le transfert de données d'une source à une destination. Lors d'un pipeline ELT, il est possible d'appliquer des transformations uniquement après que les données soient chargées.
En effet, un pipeline ELT permet le traitement des données par lot, ou par batch processing, à travers ces trois différentes étapes :
- Extract : Cette étape consiste à identifier puis extraire les données depuis une source choisie au préalable.
- Load : Après avoir extrait les données, la deuxième étape est alors d’insérer les données dans la destination cible.
- Transform : Cette dernière étape consiste à transformer les données récemment extraites et ainsi appliquer des modifications, telles que des agrégations par exemple.
A noter cependant qu'Airbyte permet de faire les 2 premières parties (Extract & Load) mais doit s'accompagner d'un outil pour transformer la donnée, généralement dbt car il existe une intégration entre les 2 plateformes.
Le but principal d'un pipeline ELT est de standardiser et de centraliser les données. Il permet de collecter des données provenant de diverses sources vers une destination unique, regroupant ainsi l'intégralité des informations dont une entreprise a besoin au sein d'un environnement centralisé.
L'utilisation d'un pipeline ELT traditionnel peut s'avérer coûteuse pour une entreprise. En effet, la maintenance et le développement de code personnalisé en fonction des besoins spécifiques de l'entreprise peuvent rapidement engendrer des dépenses importantes, surtout lorsque plusieurs développeurs sont nécessaires pour gérer quelques pipelines seulement.
De plus, les modèles d'ELT existants - souvent basés sur le volume de données - peuvent devenir très onéreux pour les entreprises qui gèrent de grandes quantités de données. Enfin, les fournisseurs d'ELT traditionnels ne proposent généralement pas un grand choix de connecteurs, limitant ainsi les options de collecte de données.
Airbyte, étant une plateforme open-source, offre l'avantage d'un accès direct au code pour les utilisateurs. Cela permet de résoudre les erreurs de code de manière autonome, sans avoir à recourir à un support externe. De plus, la plateforme propose une large gamme de plus de 300 connecteurs, permettant aux utilisateurs de collecter des données depuis une multitude de services.
Airbyte permet même à ceux qui le souhaitent de créer leur propre connecteur en 10 min en suivant un guide low-code.
De plus, Airbyte rassemble une grande quantité de documentations vous aidant à entreprendre n’importe quelle tâche et vous expliquant comment utiliser les nombreux connecteurs disponibles sur la plateforme.
Pour finir, l’équipe d’Airbyte est présente sur un slack dédié pour vous assister, mais également un github avec un nombre de dépôts de données appelés “repositories” pour différents codes et installations selon vos besoins.
Mettre en place un pipeline ELT de Google Search Console vers BigQuery avec Airbyte

Pourquoi utiliser Airbyte pour les données de Google Search Console ?
Il faut d’abord noter qu’il est possible de faire un export de la Search Console à BigQuery via la Search Console directement. Néanmoins, cet export permet l’accès aux données à la date faite de l’export et non aux données antérieures.
Lorsque vous faites l’export de Google Search Console vers BigQuery pour chacun des domaines voulus, un dataset est créé par propriété avec deux tables et un ExportLog.

Dans la table searchdata_site_impression sont présentes les données propres au domaine de cet export.
La table searchdata_url_impression est, quant à elle, un peu plus complète car elle répertorie les informations reliées au domaine mais agrégées par URL. De plus, cette table présente les queries renseignées par les utilisations ainsi que d’autres informations.
Une fois ces exports faits, il est possible de créer une base de données, une “rollup” regroupant les données de l’intégralité des exports pour chacun des domaines via BigQuery avec une query SQL.
Ensuite, il faut s’assurer que cette base de données est alimentée dès lors que de nouvelles données sont incrémentées dans les dataset searchconsole_*. Cela est possible en créant une Cloud Function qui se déclenche à chaque fois que de nouvelles données sont disponibles dans les exports. Ainsi, la rollup est mise à jour et vous disposez de l’intégralité des données des exports faits par la Search Console.
La rollup peut ressembler à ça :

Mais pourquoi utiliser Airbyte pour ces données ?
Comme mentionné précédemment, il est possible d’avoir une Rollup regroupant l’intégralité des données des exports de la Search Console. Néanmoins, la date la plus ancienne des exports correspond à la data à laquelle l’export à été créé.
L’intérêt d’utiliser Airbyte en complément et de récupérer les données antérieures à la date de l’export.
En effet, l’API de la Search Console dispose des données allant jusqu'à 16 mois d’historique.
Une fois que une Rollup regroupant toutes les données actuelles à été créé, il peut être intéressant de recueillir également les données historiques de la plateforme.
Comment utiliser Airbyte pour les données historiques de la Search Console
Nous allons donc montrer étape par étape comment utiliser Airbyte pour récupérer ces données historiques de la Search Console et les retrouver dans BigQuery.
Pour cette démonstration nous avons décidé d'utiliser le connecteur Google Search Console et donc requêter les données historique de la Search Console.
Il faut savoir que Airbyte peut être utilisé et déployé en local, sur votre propre ordinateur, ou bien en utilisant Google Cloud Platform (GCP) par le biais d’une machine virtuelle. Pour cette démo, nous allons utiliser une machine virtuelle. Il est possible d’utiliser Airbyte en local sans utiliser de machine virtuelle, pour faire une requête à faible données ou sur un seul domaine.
Si vous voulez requêter les données d’une longue liste de domaines qui auraient chacun un volume de données conséquent, une machine virtuelle est conseillée. En effet, la requête de Airbyte pourrait prendre plusieurs heures voire même plusieurs jours, selon le volume de données.
Lors des requêtes faites en local, il faut s’assurer de ne pas avoir de problèmes de connexion type wifi, ou bien de batterie sur l’ordinateur qui pourrait stopper cette requête. Cela ne permettrait que de retrouver la moitié des informations dans BigQuery dans le désordre.
Le but de la machine virtuelle est donc de s’assurer que la requête soit faite dans le cloud sans se soucier de perte de données ni de potentiel souci de connexion.
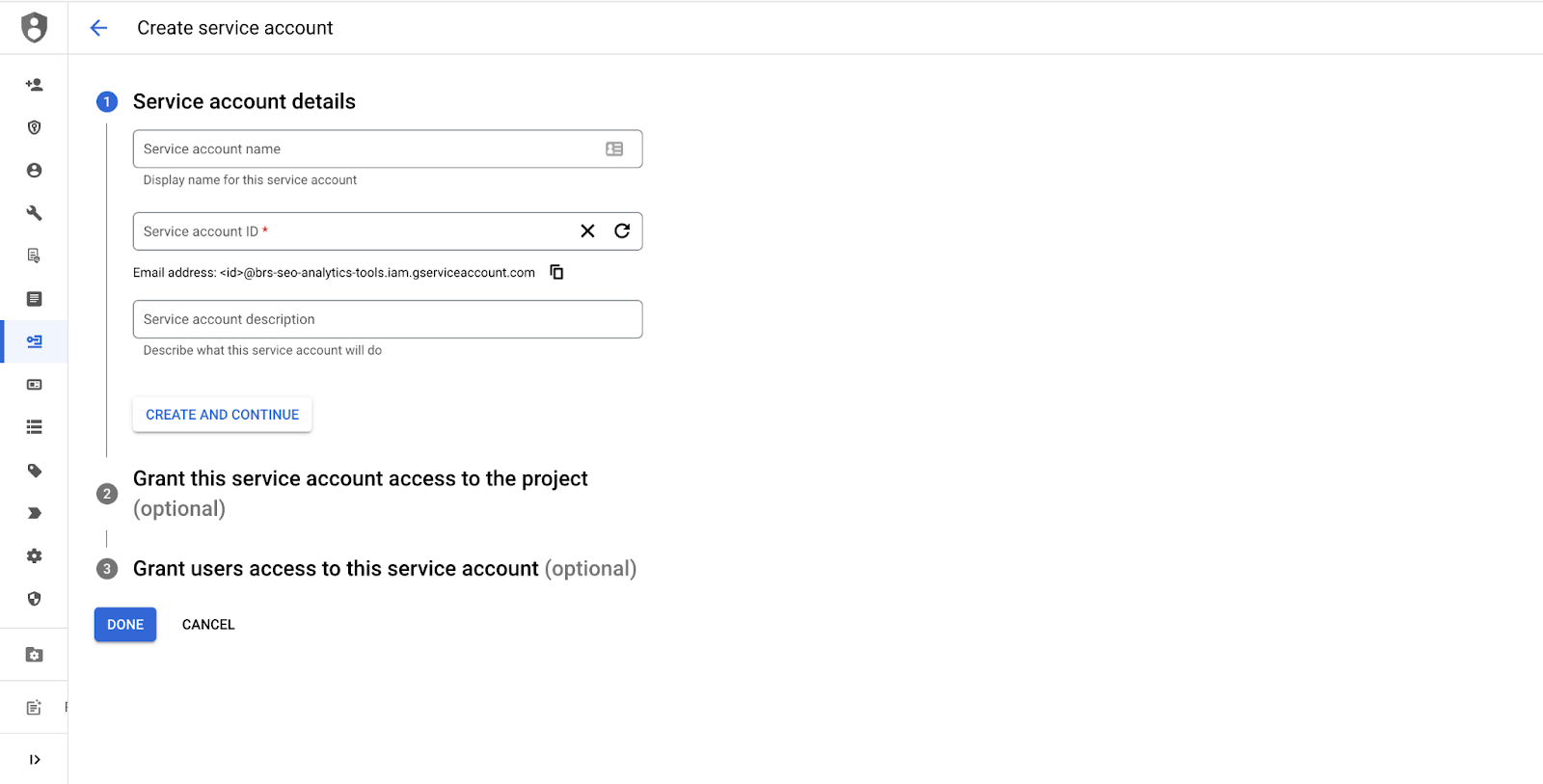
1/ Créer un service account
La première étape est de créer un service account appelé “Google Search Console service account” sur le projet GCP dans lequel vous souhaitez retrouver ces données. Ce service account nous permettra de requêter les données dans l’API de Google Search Console.
Il faut s’assurer que ce service account soit également ajouté sur la plateforme de la Search Console avec un “accès limité”. En faisant cela, nous assurons la liaison entre GCP et Google Search Console.
2/ Générer une clé liée au service account
Une fois ce service account créé, il faudra générer une clé JSON et bien la conserver, elle nous sera utile pour une étape ultérieure.

3/ Créer une machine virtuelle sur GCP
Maintenant que le service account à été créé, nous pouvons commencer à installer et connecter Airbyte au project GCP en suivant la documentation fournie par Airbyte.
A noter que si vous n'utilisez pas GCP mais plutôt AWS, Oracle ou Azur par exemple, Airbyte vous fournit également une documentation dédiée pour chacun de ces outils.
La documentation d’Airbyte explique quel type de machine créer en fonction du besoin.
Dans le cadre d’un test: une machine e2.medium avec une provision de 30 Gb minimum est requise. Pour un déploiement sur un environnement de production : une machine n1-standard-2 est nécessaire.
Toutes les étapes qui vont suivre sont présentes sur ce lien.
4/ Configuration de l’environnement
Une fois la machine virtuelle créée, nous pouvons procéder à la configuration de l’environnement. Cette étape est à réaliser sur le terminal de votre ordinateur.
- Project ID et Machine virtuelle
Tout d’abord il faut référencer les variables nécessaires telles que le project_id du project GCP et le nom de la machine virtuelle. Dans notre contexte, le nom que nous avons donné à la machine virtuelle est tout simplement “airbyte”.
Toutes les lignes de code présentées dans cet article sont à entrer dans le terminal de votre ordinateur.
- Installation de Google Cloud SDK
Une fois que l’id projet et le nom de la machine ont été renseignés, vous pouvez procéder à l’installation de gcloud.
- Choix de la machine virtuelle
Rentrez le code ci-dessous dans le terminal et suivez les instructions. Vous allez être amené à vous connecter à votre compte Google afin que la liste des projets auxquels vous avez accès s’affiche. De même pour la liste des machines virtuelles présentes dans le projet.
- Connection à la machine virtuelle
- Installation de Docker sur la machine virtuelle
Lancez ce code et attendez que l’installation soit terminée.
- Installation de docker-compose
- Fin
Une fois que toutes les étapes précédentes ont été faites, quittez la machine virtuelle en entrant “logout”.
5/ Installation et initialisation d’Airbyte
- Connection à la machine virtuelle
- Installation d’Airbyte sur la machine virtuelle
Suite à ce code vous devriez voir quelque chose comme cela :

- Fin
6/ Connection à Airbyte
- Création d’un tunnel SSH pour connecter la machine virtuelle sur GCP à Airbyte
Maintenant que tout est installé, nous pouvons créer le tunnel SSH pour lier la machine GCP à la plateforme Airbyte et donc commencer à utiliser les connecteurs.
- Vérification de la connection à la plateforme Airbyte
Connectez vous à ce lien : http://localhost:8000 sur votre moteur de recherche, vous devriez avoir accès à la plateforme Airbyte.
Si le lien vous demande de sign in les credentials sont :
Username : airbyte
Password : password
7/ Utilisation de la plateforme Airbyte
Maintenant que toute la configuration est terminée, il est temps d’utiliser un connecteur et de requêter les données. Tout d’abord, en cliquant sur “Create your first connection”, nous allons avoir accès à la liste complète des connecteurs disponibles.
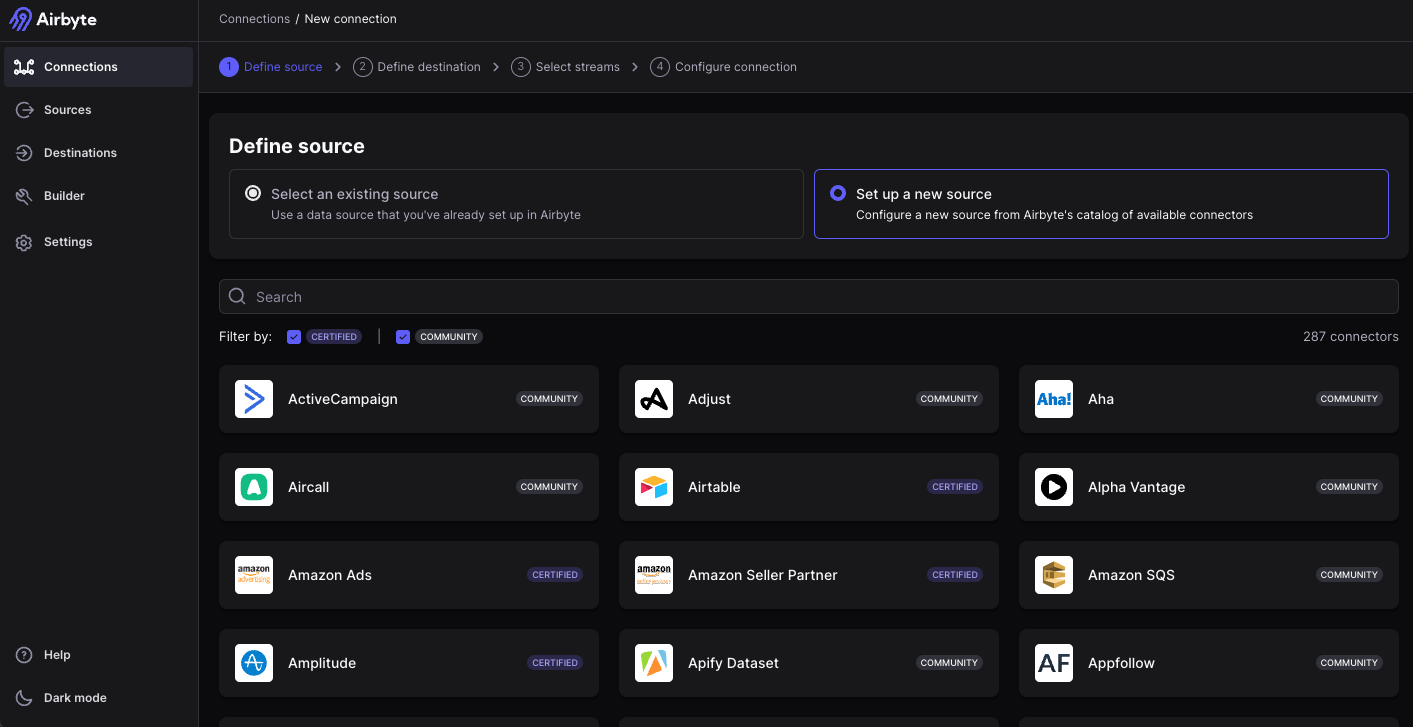
Il suffit donc simplement de chercher “Google Search Console”.
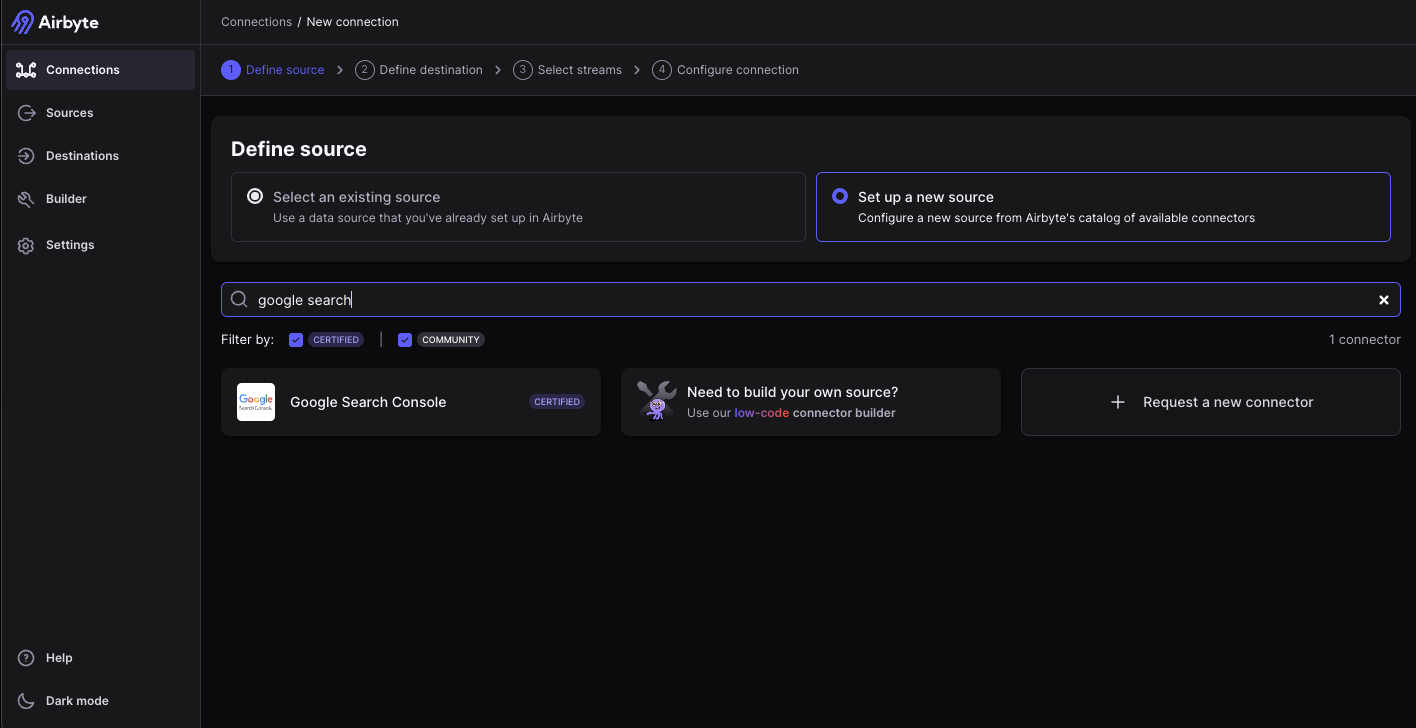
En cliquant dessus nous allons pouvoir commencer à configurer la connexion avec Google Search Console. La configuration se fait en 4 étapes.
- Définir la source de données
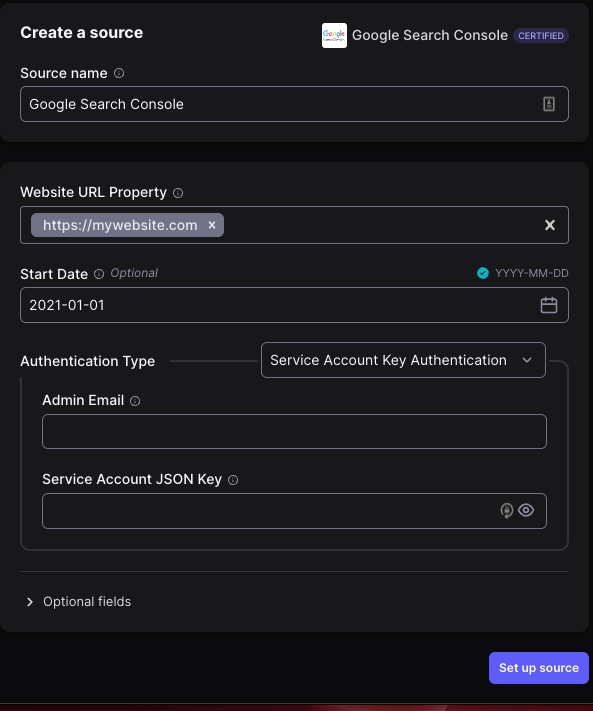
Pour cette étape, il faut donc référencer le différents domaine des sites où vous voulez requêter les données Search Console, la date du début des données et le type d’authentification.
Si vous avez créé un service account dans le but de requêter les données, c’est ici qu’il faudra renseigner l’adresse mail du service account ainsi que la clé JSON créée en première étape de cette démonstration.
Il faut copier et coller l'intégralité de la clé JSON qui vous a été fournie.
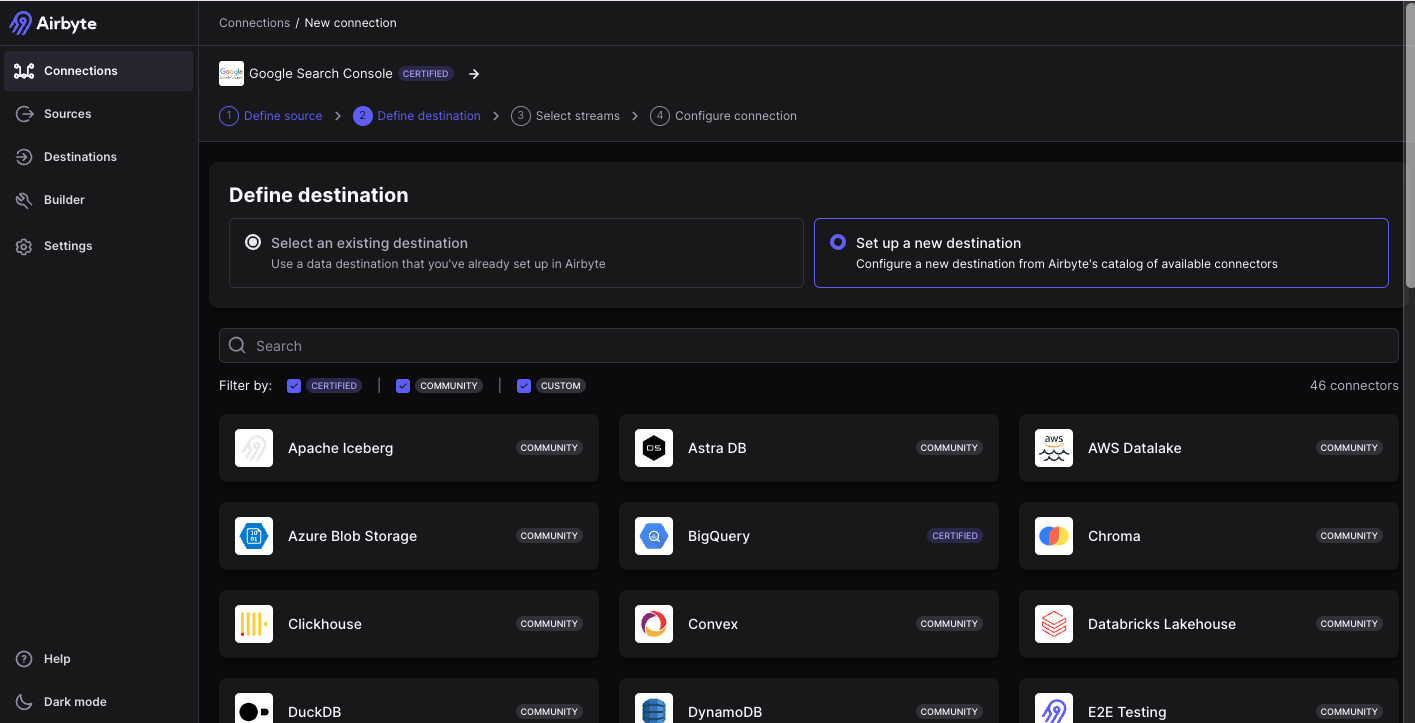
- Définir la destination
Dans cette démonstration nous allons choisir BigQuery comme destination afin de retrouver les tables de données Search Console dans BigQuery.
Une fois BigQuery sélectionné, il faudra configurer la destination en renseignant le project_id GCP où envoyer les données, ainsi que le dataset en question.

Après cela, il faut spécifier la manière dont les données devront être uploadées sur BigQuery. Les deux options sont : Via un Bucket dans Cloud Storage ou par SQL Insert (pas recommandé).
Nous allons donc choisir Cloud Storage et créer un bucket.
Une fois le bucket créé dans Cloud Storage, nous pouvons renseigner les informations relatives à ce bucket dans Airbyte.
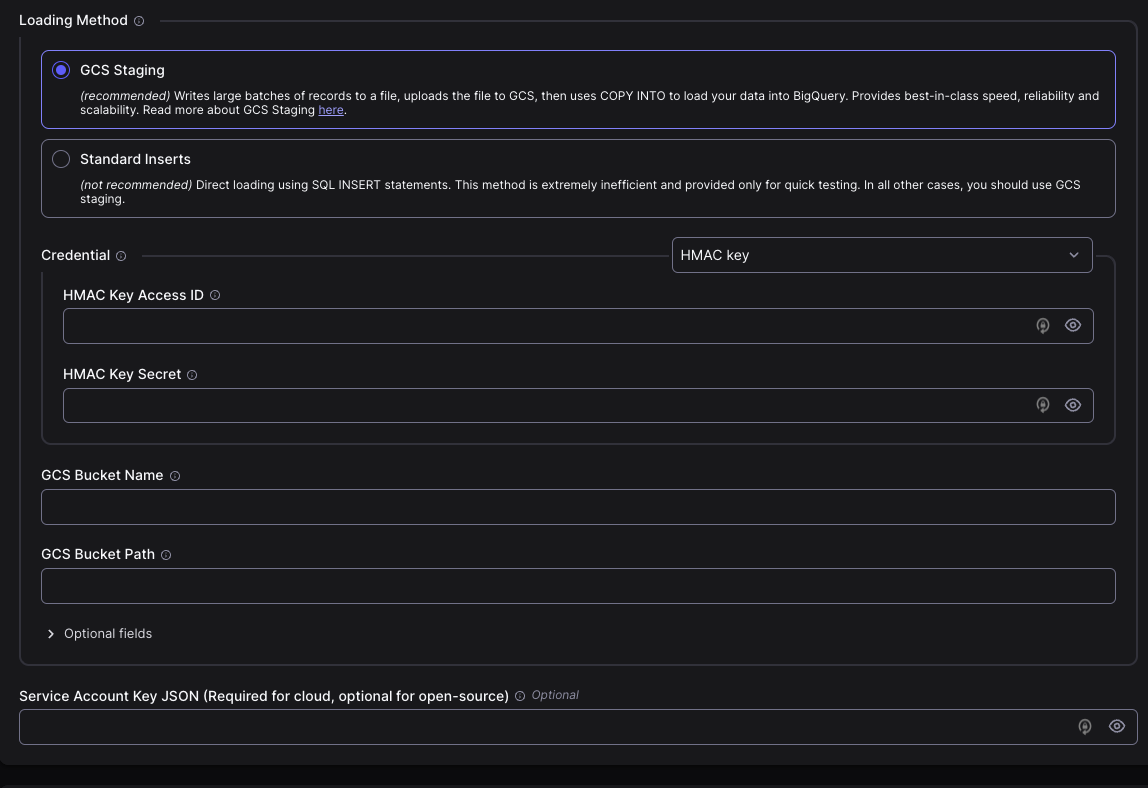
Ensuite, vous pouvez générer une clé pour le service account dédié dans l’onglet Settings > Interpretability dans Cloud Storage.
- Sélectionner les flux de données à récupérer
À cette étape, vous pouvez choisir les tables à récupérer grâce à Airbyte, voici la liste des tables possibles :
- Sites : Cette table stocke des informations de base sur les sites web que vous avez vérifiés dans Google Search Console.
- Sitemaps : Cette table stocke des informations sur les sitemaps que vous avez soumis à Google Search Console pour chaque site web.
- Full Analytics report : Cette table capture un ensemble complet de points de données Search Console
En ce qui concerne les tables ci-dessous, elles se concentrent sur des dimensions spécifiques dans le rapport d'analyse complet, offrant une analyse plus approfondie des métriques de performance par country, date, device, query et page :
- Analytics report by country
- Analytics report by date
- Analytics report by device
- Analytics report by page
- Analytics report by query
- Analytics keyword report
- Analytics keyword report by page
- Analytics keyword report by site
- Analytics page report
- Analytics site report by page
- Analytics site report by site
Il est également possible de créer un rapport personnalisé et de choisir les dimensions souhaitées parmi celles-ci :
- country
- date
- device
- page
- Query
- Création de la connection et récupération des données
Une fois vos tables choisies vous pouvez cliquer sur “Set up Connection” et les données vont commencer à se requêter de Google Search Console vers BigQuery.
Vous pourrez donc retrouver les tables que vous avez sélectionnées à l’étape précédente, dans BigQuery. Il est possible d’ajouter ces données à votre Rollup de données Search Console en utilisant une query SQL tel que :
Pour regrouper les données de site dans la table site_impressions :
Pour regrouper les données globales url dans la table url_impressions :
Il faut savoir néanmoins que les données présentes dans les tables sont seulement les données non anonymisées, donc les données pour lesquelles la query est visible. Néanmoins, pour avoir l’intégralité des données historiques disponibles dans l’API et donc avoir des résultats plus fiables, il faudrait pouvoir récupérer les données anonymisées. Pour obtenir ces dernières, une certaine manipulation dans BigQuery est nécessaire.
Optimize Matter est un partenaire certifié Airbyte et peut vous assister pour une intégration de données réussie. Contactez-nous dès aujourd'hui pour exploiter pleinement le potentiel de vos données et recueillir les données non anonymisées et anonymisées pour avoir un rapport plus complet.

![[Digest Août 2025] Google Marketing Platform features](https://cdn.prod.website-files.com/619cd7bec0ec7450708f1b7e/69afec130961487926a7cdfa_Digest_Aout_2025_Optimize_matter_1x.webp)
![[Digest Juillet 2025] Google Marketing Platform features](https://cdn.prod.website-files.com/619cd7bec0ec7450708f1b7e/69afee4c670083e8a68398fe_expertise-data-google-marketing-platform.webp)
![[Digest Juin 2025] Google Marketing Platform features](https://cdn.prod.website-files.com/619cd7bec0ec7450708f1b7e/69afef779957e51de04acb25_expertise-google-analytics-tag-manager-looker-studio.webp)