
Maintenant que nous avons exploré le potentiel de l'outil dans le premier article de la série, cette visite guidée de l'interface vous aidera à comprendre et utiliser Dataform selon les bonnes pratiques. Cet article s'adresse aux practitioners souhaitant configurer leur projet efficacement pour pouvoir se concentrer sur les transformations de données.
Nous allons voir ensemble dans cette article :
- La navigation dans les menus de gestion de projet
- L'exploration des menus d'espace de développement
- Organiser ses espaces de travail
- Créer son premier pipeline automatisé
- Conclusion
Vous pouvez accéder à Dataform depuis la liste des services associés à BigQuery.
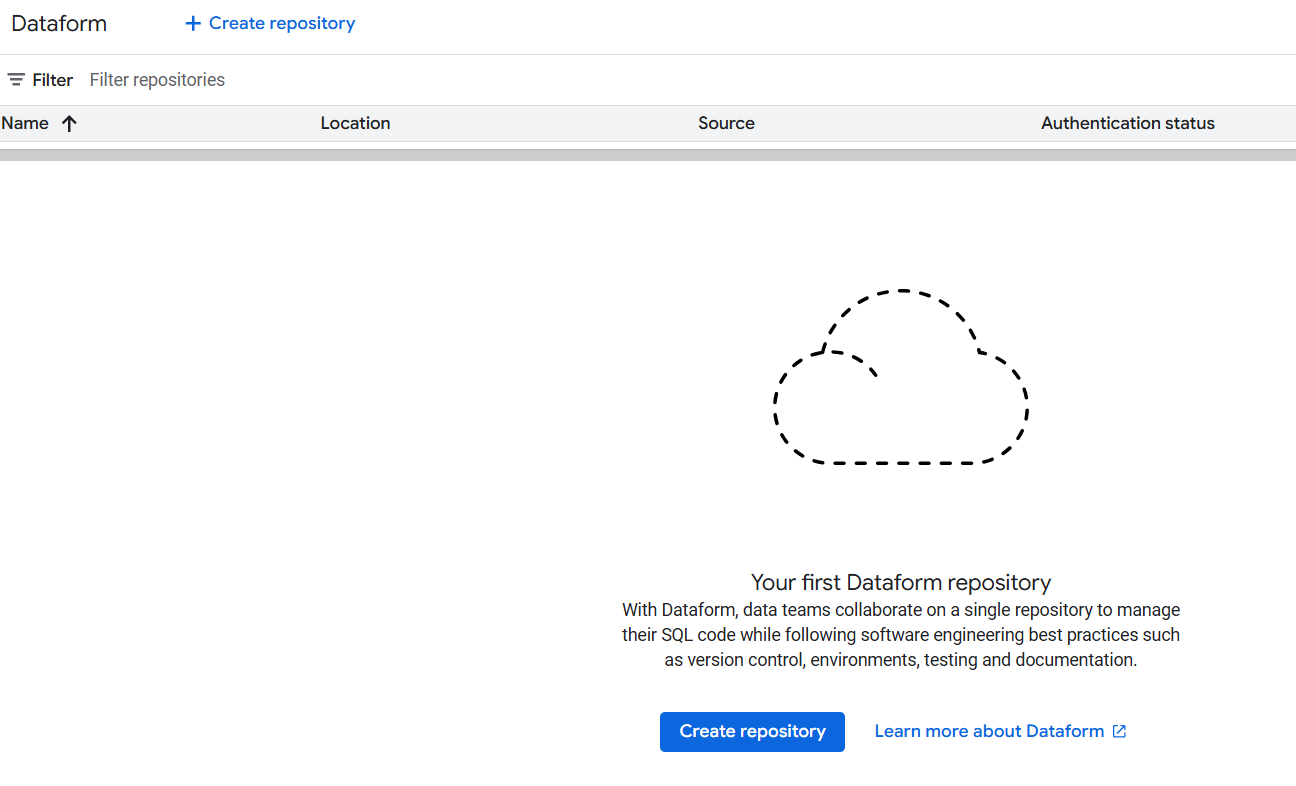
Une fois sur la page d'accueil, vous commencerez par créer un repository qui contiendra l'ensemble de votre pipeline data, depuis vos requêtes SQL jusqu'à l'orchestration, en passant par la gestion des versions.
Conseil: Attribuez un nom explicite à votre repository et n'y gérez qu'un seul projet. Par exemple, pour traiter des données GA4, nous recommandons un nom comme "analytics-ga4-processing".
Pour reprendre notre analogie Wordpress, vous allez ici créer votre "blog" :
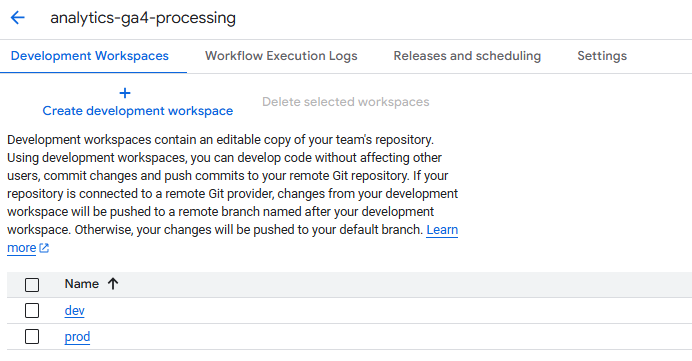
Une fois votre repository créé, vous accéderez à 4 onglets essentiels:
- Development Workspaces (Espaces de travail de développement)
- Le cœur du réacteur de votre projet où vous créez et accédez à vos requêtes
- C'est dans ces workspaces que vous rédigez votre code et développez vos transformations
- Workflow Execution Logs (Journaux d'exécutions)
- Votre tour de contrôle pour surveiller toutes les exécutions
- Permet de suivre le statut, l'heure, la durée, le workspace source et les fichiers exécutés

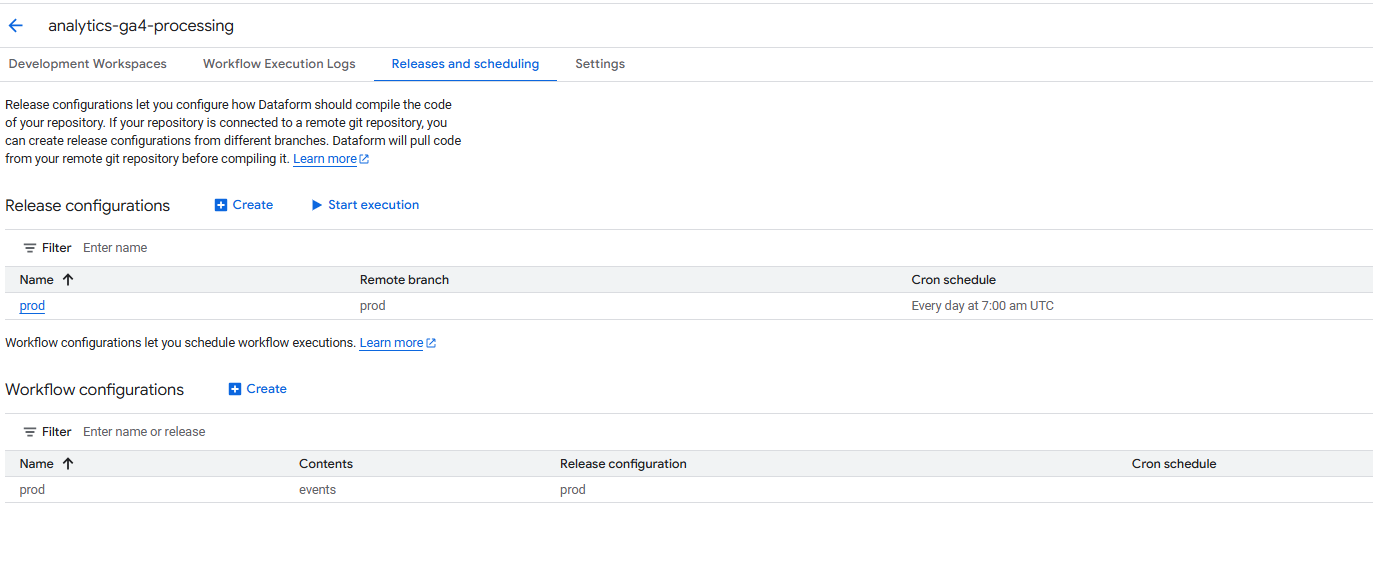
- Releases and Scheduling (Déploiement et orchestration)
- Centre de gestion des versions de votre code et de son automatisation
- Les releases compilent votre code et permettent d'ajuster des variables d'environnement à la volée
- Le code généré est stocké pour ensuite alimenter les workflows configurés qui l'exécuterons
- Settings (Paramètres)
- Gestion de la connexion GitHub que nous recommandons de mettre en place
- Configuration du système de réécriture pour modifier à la volée les datasets et tables cibles lors d'exécutions manuelles
- Particulièrement utile pour gérer différents environnements et l'évolution des pipelines
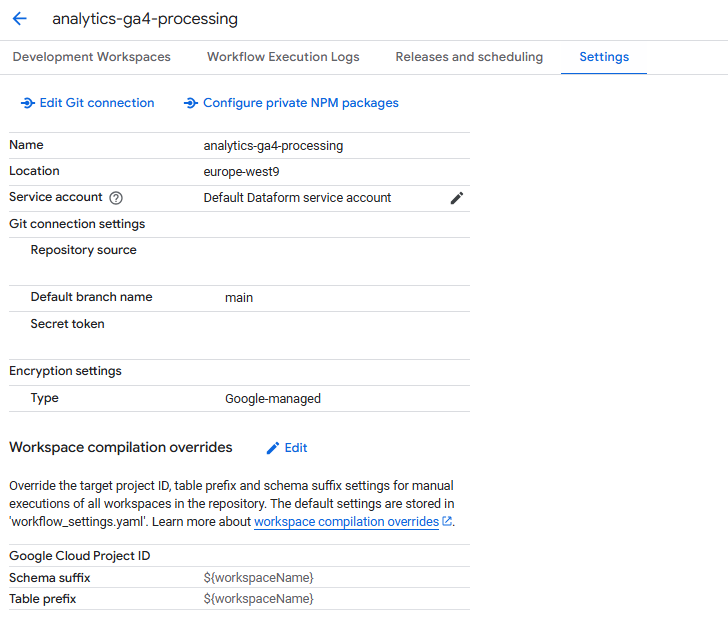
Ces 4 menus vous permettent de mettre en place et de surveiller votre Supply Chain data, avant d'aller deep dive dans les menus aidant à la production du code de transformation.
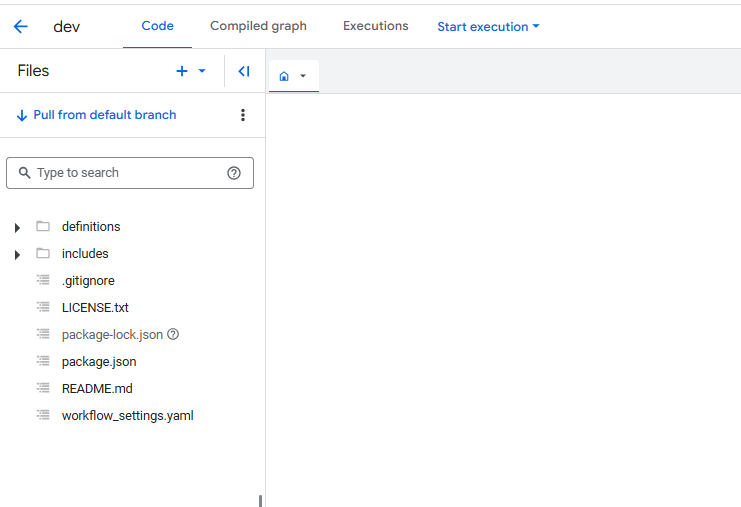
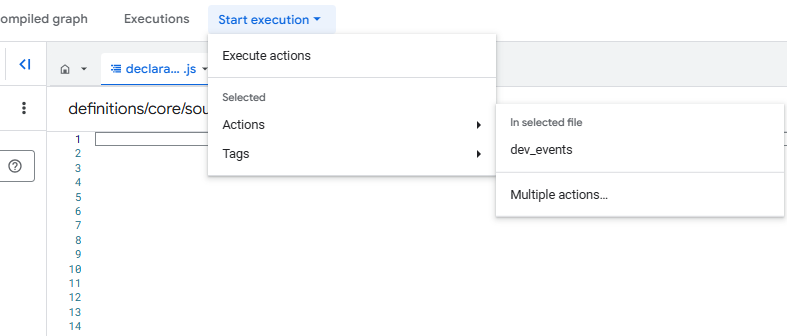
Comme souvent dans les produits GCP, une fois dans votre workspace, vous gagnez accès à encore plus de menus : Code, Compiled Graph (Graphique compilé), Executions et le bouton d'execution.
- Code contient toute votre logique de traitement de données avec une particularité importante: les fichiers .sqlx (extension propre à Dataform pour mélanger sql et js) ne sont compilés que s'ils se trouvent dans le dossier "definitions".
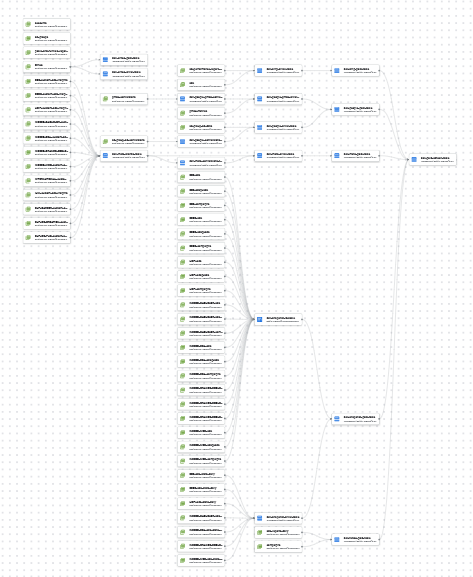
- Compiled Graph est la feature gadget indispensable qui visualise les dépendances entre les différents éléments de votre projet. Ces relations sont calculées automatiquement grâce à votre utilisation de la fonction ref() dans votre SQL et affichées sous forme de DAG (Directed Acyclic Graph).
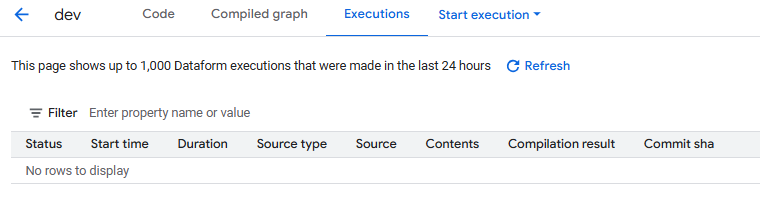
- Executions est une version plus spécifique des Workflow Execution Logs, limitée à l'historique des exécutions manuelles de ce workspace en particulier.
- Le bouton d'execution vous permet de déclencher manuellement un pipeline avec les mêmes options que celles disponibles dans la section "Release and Scheduling" pour les exécutions automatiques.
Maintenant que nous avons vu la majorité des menus disponibles et leur usage, nous allons voir ensemble comment organiser ses espaces de travail pour structurer vos produits data.
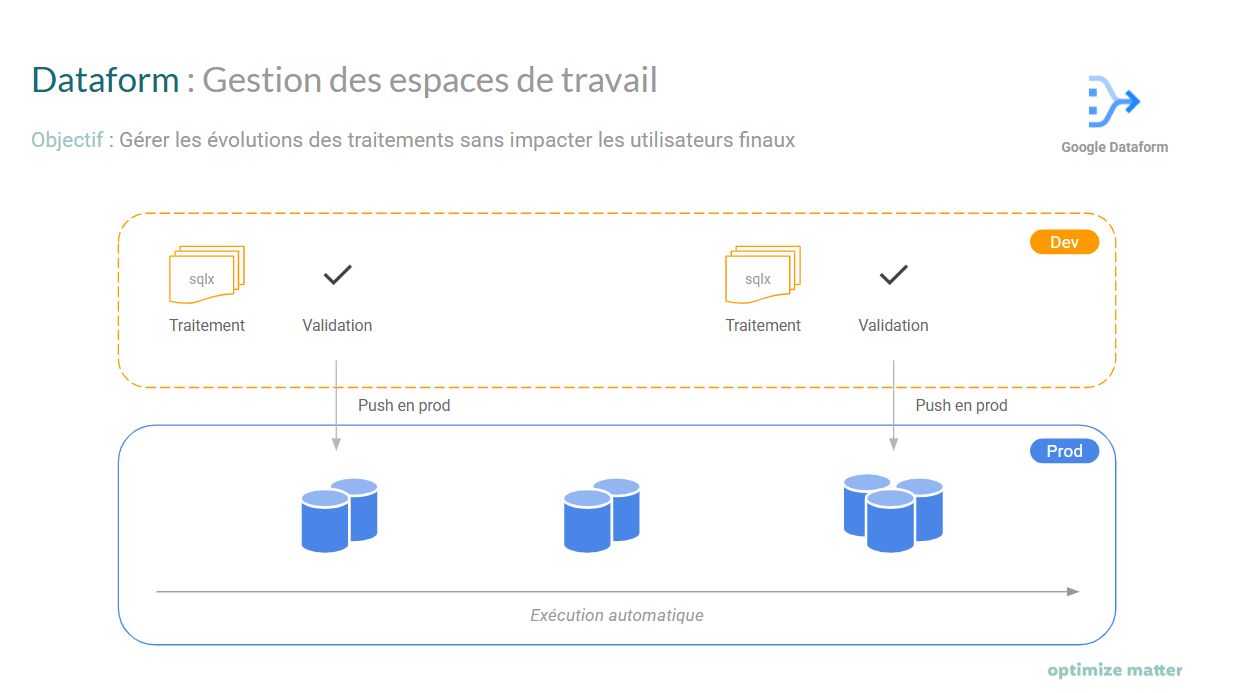
Une bonne pratique fondamentale consiste à créer au minimum deux espaces de travail distincts:
- Un environnement 'dev' pour le développement
- Un environnement 'prod' pour la production
Cette séparation présente plusieurs avantages:
- Simplification de la gestion des automatisations
- Développement et validation du pipeline en 'dev' sans perturber les utilisateurs finaux
- Aucune modification directe du code en production
Dans Settings > Workspace compilation overrides, configurez:
- Schema suffix: ${workspaceName}
- Table prefix: ${workspaceName}
Cette configuration isole vos exécutions par environnement et vous protège contre les modifications accidentelles en production. Le résultat sera:
- Deux datasets logiques: 'votre_dataset_dev' et 'votre_dataset_prod'
- Des tables préfixées: 'dev_votre_table' et 'prod_votre_table'
Pour les exécutions automatisées, nous ajusterons ces préfixes pour que vos utilisateurs finaux n'accèdent qu'au dataset "votre_dataset" et à la table "votre_table" sans préfixe.
L'architecture résultante ressemblera à ceci:
Cette structure inspiré de la gestion de développement de logiciels prend tout son sens à l'usage quand vous allez institutionnalisez vos pipelines data.
Pour déployer votre premier pipeline vous devez commencer d'abord par écrire des transformations de données. Dataform propose une initialisation de votre workspace avec des fichiers par défaut pour gagner du temps.
Voici quelques conseils pour optimiser ce contenu par défaut :
- Modifiez le fichier workflow_settings.yaml et remplacez la variable defaultLocation par votre localisation préférée (ex: "europe-west9").
- Dans le dossier "definitions", créez quatre sous-dossiers:
- "01_sources": pour déclarer vos jeux de données sources
- "02_intermediates": pour les étapes intermédiaires de traitement
- "03_outputs": pour finaliser vos produits data
- "assertions": pour rédiger vos tests de qualité
- Dans le dossier "includes", ajoutez:
- constants.js: pour vos constantes JavaScript
- functions.js: pour vos fonctions utilitaires JavaScript
Pour automatiser votre pipeline:
- Accédez au menu Release and Scheduling
- Créez une release "dev" et indiquez "dev" dans le champ Schema suffix
- Votre release compilera le code de votre branche selon la fréquence choisie
- Créez ensuite une Workflow Configuration "dev" basée sur votre release
- Définissez la fréquence d'exécution et les actions SQL à exécuter
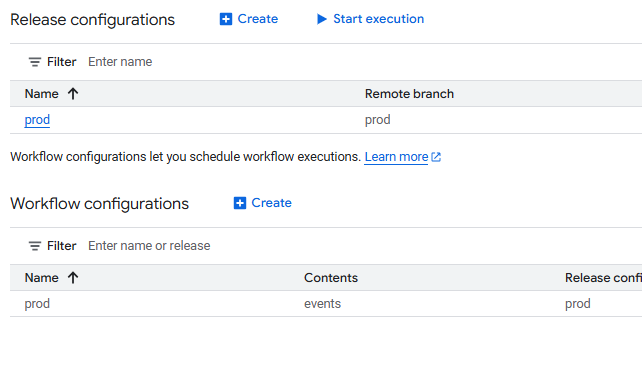
En quelques étapes vous avez un processus d'exécutions de votre code automatisé pour pouvoir maintenant vous concentrer sur les traitements de données.
Dataform offre une courbe d'apprentissage accessible pour les transformations de données, mais nécessite une attention particulière à la structuration de projet. Ce guide vous a fourni les bonnes pratiques essentielles pour:
- Créer des environnements correctement isolés
- Mettre en place des automatisations fluides
- Assurer une gestion sereine de vos produits data
Notre prochain article analysera un exemple concret: le package GA4 Dataform open source, qui vous permettra de voir ces principes appliqués dans un cas d'usage réel.

![[Digest Août 2025] Google Marketing Platform features](https://cdn.prod.website-files.com/619cd7bec0ec7450708f1b7e/69afec130961487926a7cdfa_Digest_Aout_2025_Optimize_matter_1x.webp)
![[Digest Juillet 2025] Google Marketing Platform features](https://cdn.prod.website-files.com/619cd7bec0ec7450708f1b7e/69afee4c670083e8a68398fe_expertise-data-google-marketing-platform.webp)
![[Digest Juin 2025] Google Marketing Platform features](https://cdn.prod.website-files.com/619cd7bec0ec7450708f1b7e/69afef779957e51de04acb25_expertise-google-analytics-tag-manager-looker-studio.webp)